Rod Hilton
- Software Engineer working primarily in the JVM with Java, Groovy, and Scala with a lot of Ruby coding on the side
- Movie geek and freelance columnist for cracked.com, creator of "Machete Order"
- Voracious reader of technical books and insatiable learner
Experience
Passionate, hardworking polyglot programmer with strong CS background and over a decade of experience following good engineering principles (TDD, CI, SOLID, DRY, YAGNI) developing scalable backend services, web applications, and client applications
Staff Software Engineer (2023-Present)
Compute interfaces team member, building segmentation and augmentation tools for customer marketing campaigns

Tech Lead, Backend Engineering (2021-2023)
Social team lead, building Epic Online Services for friends, messaging, partying, group-forming, clip-sharing within games

Staff Software Engineer (2017-2021)
Core Tweet Service backend team, storing and serving all Tweets within Twitter at massive scale

Principal Engineer (2011-2017)
Cross-Platform team, built Common Services Tier middleware service layer and customer-facing web portals.

Technical Lead (2008-2011)
Agile Lifecycle Management team, developed work and ticket tracking system for scaled enterprise agile adoption.

Senior Software Engineer (2007-2008)
OpenLogic Enterprise team, developed SaaS web applications to manage open source across corporations as well as open source scanning desktop application utilizing Java, Ruby, Rails, and JavaScript.

Senior Software Developer (2004-2007)
eDriverData team, built console application for collecting and linking data from public records databases for background screening and debt collection utilizing Java, ColdFusion, SQL Server.

Education
"Perpetual student" taking supplementary MOOC classes online, attending professional conferences annually, and reading constantly
M.S., Computer Science
Specialization in Machine Learning, Theory, and Algorithms

B.S., Computer Science
Focus on Systems

Skills
- Accomplished: Java, Scala, Git, Groovy, Ruby
- Advanced: Python, Spring, ANTLR, HTML/CSS, LaTeX, REST, Kafka, Mathematica, JavaScript, Grails, AWS, Go, MySQL, SOAP, Terraform
- Novice: Redis, AngularJS, TypeScript, Thrift, Kubernetes, PostgreSQL, Hadoop, Oracle, SBT, memcached, Jenkins, hazelcast
- Desired: Kotlin, ElasticSearch, Spark, Cassandra, GCP, Rust, F#
Articles
Assorted writings, mostly ported over from my blog "Absolutely No Machete Juggling"
Retro Gaming Setup: A Beginner's Guide
Strap in folks, this sucker's over 10,000 words for, like, Mario and stuff.

There Are Great Tools in Your bin/ Directory
Every Java developer is familiar with javac for compiling, java for running, and probably jar for packaging Java applications. However, many other useful tools come installed with the JDK. They are already on your computer in your JDK’s bin/directory and are invokable from your PATH
Smart Assholes: A Probing Examination
It's better to have a hole in your team than an asshole

Strengths Only: A Peer-Review Philosophy
If you can't find a way to phrase your constructive criticism so that it wouldn't offend the recipient, the absolute last person on the planet you should share your poorly-worded feedback with is the person who signs their paychecks.

Programming Podcasts: A Roundup
A number of people have asked me what programming podcasts I listen to, and they’ve generally been pretty happy with the breadth and volume of my response. I thought it would be a good idea to share all of these here on my blog in case other programmers are searching for some good podcasts.
A Branching Strategy Simpler than GitFlow: Three-Flow
Three-Flow has exactly three branches - no more, no less: master, candidate, release.

Software Engineering Guiding Principles - Part 2
Here are five more Guiding Principles I use when making technical decisions as a software engineer. You can also check out Part 1.

Software Engineering Guiding Principles - Part 1
I find that I repeat myself often at work. There are a handful of things I say so often when discussing decisions that I’ve been called out for it on occasion for acting like a broken record.

Star Wars Machete Order: Update and FAQ
Wow, this Machete Order thing got big! After the post first “went viral” and got mentioned on Wired.com, I started getting around 2,000 visitors to it per day, which I thought was a lot. But then in the months before Star Wars Episode VII: The Force Awakens was released, it blew up like Alderaan, peaking at 50,000 visitors DAILY. This year, over 1.5 million unique users visited the page. It’s been nuts.

Top 10 Career-Changing Programming Books
When I graduated with a Computer Science degree ten years ago, I was excited to dive into the world of professional programming. I had done well in school, and I thought I was completely ready to be employed doing my dream job: writing code. What I discovered in my very first interview, however, was that I was massively underprepared to be an actual professional programmer. I knew all about data structures and algorithms, but nothing about how actual professional, “enterprise” software was written. I was lucky to find a job at a place willing to take a chance on me, and proceeded to learn as much as I could as quickly as I could to make up for my deficiencies. This involved reading a LOT of books.

Getting "Real Work" Done
Of all the annoying things in this industry, there’s one occurence I see so often that it dwarfs all others, at least in frequency. I see this happen so often that I’ve been unable to post this despite having saved it to my Drafts nearly five years ago, because there’s never been a point in time where posting it wouldn’t make a co-worker think I was talking about them.

Traveling Salesperson: The Most Misunderstood Problem
Whenever people start talking about NP-Complete problems, or even NP problems, one of the first examples they reach for is the classic Traveling Salesperson Problem. TSP makes sense because it intuitively can’t be solved quickly due to how difficult the problem sounds, so it’s reasonable for people to use it in discussions about P versus NP.

Computer Science and Telescopes
Whenever there is a discussion about what Computer Science is and what it is not, it is a near-certainty that a particular quote will soon be used.

The Star Wars Saga: Introducing Machete Order
Watch them in this order: IV, V, II, III, VI. Skip I.

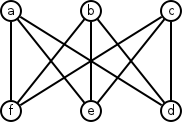
Why The Complete Bipartite Graph K3,3 Is Not Planar
The graphs \(K_5\) and \(K_{3,3}\) are two of the most important graphs within the subject of planarity in graph theory. Kuratowski’s theorem tells us that, if we can find a subgraph in any graph that is homeomorphic to \(K_5\) or \(K_{3,3}\), then the graph is not planar, meaning it’s not possible for the edges to be redrawn such that they are none overlapping.
I Broke Your Code, And It's Your Fault
One of the most enjoyable parts of my last job was that we hired a lot of junior developers and interns. I really enjoy working with younger people than me, because they’re as eager to learn new things as I am. I also really enjoy discussing technical things with them, largely for selfish reasons: explaining something to someone else makes me understand that thing much better.
Magic Variables Aren't Always Magic
Software development is a strange beast sometimes. Despite the fact that it is not predictable enough or constant enough to qualify as true engineering, it’s often referred to as Software Engineering anyway.

Mechanics of Good Pairing
I’ve made no secret about the fact that I Love Pair-Programming. I’ve tried pair programming with a number of different setups, each one better than the last.
What Is Technical Debt?
Paul Dyson has made a blog post entitled “Technical Debt and the Lean Startup” as well as commented on my post about When To Work On Technical Debt, challenging some of my claims. I read through his post and, while it makes a number of good points, I think it ultimately advocates for a risky manner of running a business. I started typing this as a response to his comment, but realized that it was long enough to warrant a separate post, so I’d like to go through his post’s points one by one.
When To Work On Technical Debt
I hear the same complaints and concerns from all sorts of different software development organizations. It seems that development teams only suffer from a small handful of problems in the broad sense, and nearly every team seems to share them.
A Different Kind of Technical Interview
Everyone who’s been programming professionally for a while knows the standard format of the technical interview. You go in, there’s a whiteboard in the room, and you write code on it to answer questions.
Agile With a Capital “A” Vs. agile With a Lowercase “a”.
There have been a number of blog posts and discussions lately around the evils of agile. Lots of traffic recently surrounding an old post by Cedric. This stackoverflowist is switching to waterfall. Hell, agile ruined this guy’s life - HIS ENTIRE LIFE!

Finding High-Impact Areas for Refactoring
At Rally, we’ve stayed committed for the last 7 years to never telling the business that the product has to halt active development to pay down technical debt. For us, the “big rewrite in the sky” has always been off the table. Instead, we prefer to incrementally refactor and improve the existing elements of the codebase, gradually getting it to where we want it to be without ever halting feature development completely.
Avoiding The Big Design Interview Question
There is one common type of question that I think sets up both the candidate and the interviewer for failure. I’ve seen it asked by my interviewers, my co-interviewers, and even by me. The question takes this format:
You Have To Buy It Twice Before It’s Cheap
One of the most common sources of tension between product owners and developers is when product owners are surprised at how high an estimate for a story might be. Usually this tension is easy to resolve by reiterating that the product owners really have no concept of how much something should cost. However, there is one scenario I see over and over again: when a product owner protests the estimate of a story because it seems, to the PO, like it’s simply re-using an aspect of the system somewhere else.

Units are Not Classes: Improving Unit Testing By Removing Artificial Boundaries
Many developers think of unit tests as tests that test a single class. In fact, I myself once thought this way. If I wanted to write unit tests for a two-class system in which a class used another class, I’d write two unit tests. After all, if I created instances of both classes in my test, that wouldn’t really be a unit test, would it?
My Personal 3 Pillars of Job Satisfaction
As I grow through my career as a software developer, I have tried to remain aware of what makes me happy or unhappy at a job. What I decided was that there were three factors in job satisfaction, so I found myself amazed that someone else had posted something similar: Alan Skorkin explains his Three Pillars of Job Satisfaction.
Enhancement vs. Defect: More Than Pedantry
Change is inevitable in the world of software. In fact, the need for change and the related need to adapt to change are the driving forces behind the agile movement. Requests for change generally come in one of two main forms: enhancements and defects. A defect means “the software isn’t working the way it says it will”, whereas an enhancement basically means “the software isn’t working the way the customer wants.”
5 Ways To Hose Your Estimates
Everyone knows the drill with Agile: the developers put estimates on stories, and those estimates are used to plan releases. Of course, some releases go awry, with the engineering team delivering far fewer completed stories than expected. When this happens, people start to ask “why are our estimates so inaccurate?” What many don’t realize, however, is that this is the wrong question. Estimates don’t need to be accurate, they need to be consistent.
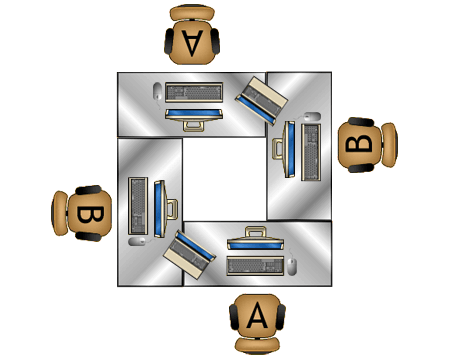
I Love Pair-Programming
My current job is the first one where I’ve ever pair-programmed. I actually recall interviewing for it, and I was asked if I had pair-programmed before. I said sure, occasionally I would pull another developer over to my desk to help me and we’d sit together to figure it out. This apparently was a decent enough answer to the question that I got the job, but now that I’ve been pair-programming nearly full-time for five months, I’ve determined that what I was doing before was definitely not real pair-programming.
Java Compiler Generating Secret Methods
I’m going to show you a little trick that will add two methods to any Java class, without actually defining them. Furthermore, these methods will be given package visibility, accessible by any class in the same package.
The Innovation Paradox
A number of prominent software developers have written essays and blog postings explaining how important it is to embrace new technologies, encourage developers of ‘fringe’ languages, and the like. There are a number of articles that I’m too lazy to look up that make these assertions and similar ones. Here’s one. Here’s another. It is extremely common for people to argue that the most important thing when developing software is to use the right tool for the job; if Python is the best language for a task, then use it instead of a more popular language. This is true to a very large degree, but this viewpoint misses a crucial practical aspect to software development.
Projects
Various public projects I work on from time to time.
JaSoMe (Java Source Metrics)
Zero-compilation Object Oriented Metrics analyzer for Java code, 13 forks on GitHub
console_table
Ruby gem for formatting and printing tabluar data in commandline scripts, over 100,000 downloads
Rectangle Visibility
Uses Genetic Algorithms to search for solutions to Rectangle Visibility problem
Trajectories
A Scala application that uses Linguistic Geometry concepts to quickly compute trajectory positions for chess boards
Geneticrypt
Extensible framework with CLI and GUI for using genetic algorithms to decrypt messages encrypted with a substitution cipher